Let’s face it, we all want to rank well (get a decent amount of exposure) in Google search. In fact, some people have even built websites hoping that they will succeed online with Google traffic alone.
While I don’t necessarily agree with this type of plan because it can be nerve wrecking knowing that your future is in someone else’s hands, I do understand why people want this traffic so badly — it’s convenient; pretty much automated; very well targeted; from my experience, it converts well and most importantly, it’s FREE!
Of course, in order to get this traffic, we need a plan and in order to setup a plan, we need to understand what we are working with. In this case, we need to try and understand Google’s ranking factors.
While there are many important factors, in my opinion the #1 factor is trust:
So why is this so important?
Well, as you already know, many people trust Google — billions of people search Google everyday. These searchers expect to find relevant and safe results. Google’s job is to give these people what they want.
Google basically has a reputation to withhold and as a result, they are not going to send their visitors to just any website. They have to get to know the website and figure out whether it is worthy of their visitors.
For this reason, if you are just starting out, know that Google will have 0 trust for you. Which means your ranking position will be very, very poor. Heck, there is a very good chance that your site won’t even rank for its name.
For example, when I first launched this site, I was only ranking for my URL (http://creatingawebstore.com/) and for the following query site:creatingawebstore.com — see the image below for details.

After 5 days, the site started to rank for its name “Creating a Webstore” but I was the last result (#10) on the page. I have attached an image so that you can see.
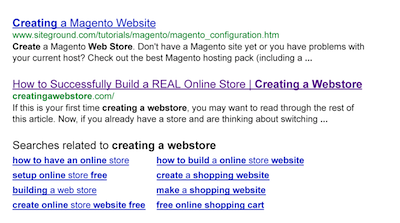
Now since the site didn’t even rank first for its name, can you imagine how inner pages were ranking? I can tell you right now, that until this site earns some trust, the rankings will be poor.
In fact, I am lucky that the site even ranks for its name on the first page. Which is probably due to: the name not being competitive, original content, an SEO friendly setup, no keyword stuffing…
I describe some of these things further down in the article.
Now if your site’s name is an exact match (as expained in this article), it can take you longer to rank on the first page. So please don’t judge your site’s ranking based on this one, because all sites are different. I have seen sites that weren’t able to rank #1 for their names even after months or years have passed due to their domain name containing highly competitive keywords.
Of course, aside from the name, you will also want your site ranking for terms that are related to your products or services.
For example, if you sell polka dot ties, you basically want to rank for this term as well as other related terms — e.g., green polka dot ties, yellow polka dot ties etc.
But in order for this to happen, you need to earn Google’s trust.
So how do you earn trust?
Site age:
I strongly believe that a site’s age plays a huge role. Of course if you read a few SEO blogs, you will get the impression that links are the most important factor (which I get to later in this article) but I can tell you from experience that this alone, will not get a new site to rank for a highly competitive term.
Just search for something competitive in Google and you will see that all first page results consist of aged websites.
Of course, I am not the only one to believe that age matters. For example, many webmaster believe that there is a sandbox filter which supposedly prevents newer sites from ranking well.
Matt Cutts (head of Google’s webspam team) was actually questioned about it in this interview years ago (sandbox talks start at 01:32) and from the way I understand it, he never denied the possibility.
While Matt Cutts doesn’t necessarily say that a sandbox exists, he does say that there are certain parts of the algorithm which can be perceived as a sandbox.
Personally, I don’t really care whether a “sandbox” exists. My main concern is whether an average 1 month old mom & pop run site can rank for a highly competitive term or terms for that matter. Personally, I believe that they can’t.
In the interview I especially find the audio at 05:01 very interesting when Mike Grehan asks Matt Cutts whether it would make sense for Google to wait 9 months to rank a website.
Notice how Matt Cutts starts taking about news crawl, blog search and trust, yet never denies the possibility of having to wait an x amount of time. Instead he tells webmasters not to worry about this and to concentrate on building a great site.
Sure this interview is pretty old but I believe that this still applies today as does many other factors.
Personally, I have watched the rankings of many new sites and I can tell you that all have managed to improve their ranking as time went by. Yet none of them have managed to completely dominate the rankings in a very short period of time.
I can even back up my statement with these two Google patents: information retrieval based on historical data and ranking documents.
As an example, let’s take a look at Creatingawebstore.com. Remember how I told you that the site ranked at #10 for the term “Creating a Webstore” after 5 days. Well, today (17 days later) the site ranks #6 — below you can see an image of the results.
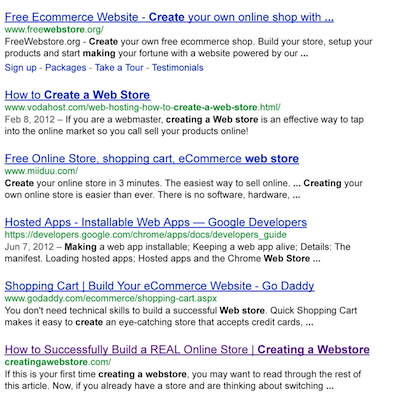
Also note that just a couple of days ago the site ranked #8. This all happened with no links and no major modifications to the site. This only goes to prove that site age does play a role in rankings.
Of course I have a long way to go before I start ranking for anything even relatively competitive. Especially since the site can’t even rank 1st for its own name but you get the point.
Luckily, you can always look at other ways to get traffic while your site matures. Personally, I’ve found these free shopping comparison sites and Bing to be a good source (so there’s an idea).
Links to your site:
If you have been reading up on ways to rank in Google, you probably know that links play a major role.
If you are not familiar with this factor, it goes something like this, say you own a jewelry webstore and a famous jewelry blog ends up mentioning your site to their readers via a link. Those readers interpret this as a recommendation, right?
Well, Google interprets this the same way.
You see, search engines bots are not human so they cannot figure out whether a site is reputable the same way that we can. For this reason, Google relies on the web’s opinion — their signal of trust.
As a result, when enough people start trusting a site, Google starts to feel more comfortable trusting the site as well.
Also if you manage to get an anchor text link that describes your product(s) or service(s), Google can interpret it as a relevancy signal. So say someone links to your site with the anchor text “wedding bands”, if your site sells wedding bands, you can end up ranking for the term or terms that contain those words.
Unfortunately, webmasters have taken links to an extreme and as a result, Google has been getting tough.
In the past it was actually relatively easy to rank for just about any term with a lot of links and keyword targeted anchor text, but as more and more people found out about this, anchor text links became more and more abused.
Things actually became so bad that people started calling them “Google bombs” which you can read more about here.
In addition to this, people started building a large number of links artificially so that they could rank faster.
JCPenny was actually amongst some of the larger businesses to get busted — this link from CNN explains everything.
So each time Google had to come along and figure out a way to stop all the manipulative tactics.
Google’s link scheme page actually goes through a list of things that can get your site penalized.
Now if you are thinking to yourself that you can get away with it (don’t worry we all do at some point), know that it’s pretty hard.
Google is at a point where it doesn’t only check for manipulation manually but also algorithmically. So if you are doing something suspicious know that Google will figure it out at some point if they haven’t already.
Of course as a webmaster, I understand that it can be difficult to get links automatically.
Sure Google says that you should just focus on creating “high quality content” because this type of content gets linked to automatically. Unfortunately, in reality, this is very difficult.
I mean how is someone going to link to you if they can’t even find you? It’s common sense that people won’t link to something that they don’t know about.
For this reason, you really have to market your site so that people can link to you.
My advice, just stay away from low quality sites, do not buy links and do not spam sites with a bunch of keyword anchor text links.
Matt Cutts also has some advice and he actually talks about getting links naturally on YouTube — check out the video below:
Also, after you’ve gotten some links, don’t worry so much about the quantity. If you can get just a couple of links from highly reputable sites, it will be worth more than 100 links from low quality sites.
Also try to get links that are relevant to your niche.
For example, if you sell flower seeds, a link from a “how to grow flowers” blog will help you tremendously because it helps Google better assess the relevancy of your site and trust it even more.
Links from your site to other sites:
This is another important factor. Many webmasters these days are afraid to link to other sites because they think it might affect their sites negatively in Google.
In reality, this can have a negative affect only if you link out to bad websites or if you sell links on your site which pass rank.
Of course, if you are not doing this, you have nothing to worry about.
For example, I link to quite a few sites on this site, but I only link to sites that I trust. So when you create links, think whether the site is safe, a good resource and whether it’s reputable. As long as you do this, you’ll be fine.
Social signals:
Facebook and Twitter have seen a tremendous amount of growth over the years and there are many others like them becoming more and more popular. On these social networks we see people discussing, liking, sharing and recommending websites all the time. As a result, it would only make sense for Google to pay attention to this information.
But in order to reduce spam, these sites have added the nofollow attribute to their links. Therefore we wonder whether Google takes any of these recommendations into account…
Well, in a webmaster Q&A video, Matt Cutts stated that they do. Matt basically goes on to say that they do use Facebook & Twitter links in their rankings as they always have.
If you doubt whether this is true due to the nofollow attribute in Facebook, know that the attribute was added in 2009 and it turns out that Matt’s video was shot in December 2010.
He also goes on to talk about reputation and the barriers that make it difficult for Google to use this information extensively — for details, take a look at the video below:
User engagement:
Many webmaster and SEOs suspect that user engagement plays a role in rankings. Personally, I believe this to be a factor as well.
While we don’t have much solid proof of this, Matt’s video below confirms the use of blocked sites data in their rankings:
In the video, I especially find it interesting when Matt says that Google can tell if the person blocking the site is “real” or spamming.
This leads me to believe that Google can also use CTR (click through rate which is shown in webmaster tools) as a popularity factor. So if someone searches for something in Google and happens to click on your site, I can only assume that this is taken into account.
Of course the visitors would also have to spend time on your site for the page to be deemed relevant to the query. After all, if it’s irrelevant, people will immediately click the back button on their browsers.
Personally, I think this is one of the easiest ways to determine relevancy.
And since Google can monitor this information for all sites listed on a particular search results page, it’s easy for them to figure out the average bounce rate for the query and which pages are relevant.
Branded searches may also help. For example, if people search for “creating a webstore” in Google and click on this site, it may be an indicator that it’s popular. After all, people are searching for my site in Google.
Of course there are also many on-page factors that play a role:
Before I go deeper into on-page factors I would like to start with the most basic.
Title tag:
The META title tag is considered to be very basic SEO but I still even to this day, come across sites that ignore it. If you are not familiar with META tags, I describe them in this article.
So in short, you want to write a title tag that briefly describes what your page is about. Sort of like how “Getting Free Google Traffic & Understanding the Ranking Factors” describes this article — it’s short and to the point (maybe not the best).
In this USA Today interview with Matt Cutts we are reminded about the importance of this tag. Matt Cutts brings up San Diego chiropractor David Klein, who couldn’t rank well in Google due to improperly filled META tags (title tag in particular).
The interview also mentions keyword stuffing which can get your site removed from Google. So don’t overdo it by repeating your keywords over and over again. Just write your titles for people. In other words, make sure that they flow naturally.
Avoid over-optimization:
While Google’s algorithm has always been good at preventing sites from ranking artificially, the Penguin update has truly taken this to the next level. For details, I recommend Search Engine Land’s article on Penguin.
Content:
If you want to rank well, make sure that your site has enough content. For example, if you are selling home improvement tools, you may want to give your expert opinion on them, show people how to use the tools or how to build projects with them.
Take Home Depot’s website as an example, they have a how-to section which provides people with plenty of tutorials. This is a great way to bring in visitors, offer valuable information and cross promote your products. In short, don’t forget what they say about the internet “it’s the information highway”.
Avoid duplicate & thin content:
Google has never been a fan of duplicate content and they are constantly telling us to create quality, original content. Their Panda update is proof of this.
Therefore, if you have a very thin site that offers nothing more than products for sale, your rankings may suffer. Especially if these products can be found elsewhere. For information on Panda and ways to safeguard your site from it, see this page which has a ton of information.
Copyright removal notices:
On 8/10/12 Google announced that sites with a high number of valid copyright removal notices will rank lower in search results.
Site speed:
While site speed doesn’t play a major role in rankings, it’s important to note that it is a factor — for more details see this link.
Crawling issues:
Sometimes a site’s ranking issues can be blamed on negligence. For example, if Google can’t get to your content, they can’t index it.
Therefore, make sure that you are properly linking to your pages, make sure that your links aren’t broken and also make sure that you’re not blocking Google with a robots.txt file.
If you ever decide to move your pages from one URL to another, make sure that a 301 redirect is being used. I show examples and explain why 301s are important in this article.
Also I don’t really know how much of an impact multiple URLs leading to your homepage can have, especially since it’s a common issue on the web. However, it’s recommended that only 1 URL leads to your homepage.
So say your homepage can be accessed from multiple URLs like the ones below:
- http://creatingawebstore.com/
- http://www.creatingawebstore.com/
- http://www.creatingawebstore.com/index.html
It is recommended that you choose a default URL and 301 redirect all other duplicate pages to it. This can also be done with the canonical link tag.
So for example, on Creatingawebstore, http://www.creatingawebstore.com/ redirects to http://creatingawebstore.com/ which is the default URL.
You should try to do this with other duplicate pages as well.
Also, if your site relies heavily on rich media, it could prevent Google from seeing the content that your visitors see. This webmaster tools help page explains how to make your site easier for Google to index.
If you have a very large store, Google might have a hard time finding all of your pages, or it may take a while for them to find all of the pages. For this reason, you may want to look into an xml sitemap which can help guide Google around your site.
So as you can see, there are many factors to consider but don’t worry since with time all this will seem like a walk in the park. I actually didn’t have a clue about Google when I first setup a website but it eventually all fell into place. Just take it one step at a time.